6장 정렬
연속된 데이터를 기준에 따라 정렬하기 위한 알고리즘
- 선택 정렬 : 처리되지 않은 데이터 중 가장 작은 데이터를 선택해 맨 앞에 있는 데이터와 바꾸는 것
- 삽입 정렬 : 처리 되지 않은 데이터를 하나씩 골라 적절한 위치에 삽입
- 퀵 정렬 : 기준 데이터를 설정하고 그 기준보다 큰 데이터와 작은 데이터의 위치를 바꾸는 방법
- 계수 정렬 : 특정한 조건이 부합할 때만 사용할 수 있지만, 매우 빠르게 동작하는정렬 알고리즘
1. 선택 정렬
처리되지 않은 데이터 중 가장 작은 데이터를 선택해 맨 앞에 있는 데이터와 바꾸는 것
- 시간 복잡도 : N번 만큼 가장 작은 수를 찾아서 맨 앞으로 보내야 하므로, $N + (N - 1) + (N - 2) + ... + 2$ 이므로 $(N^2 + N - 2) / 2 = O(N^2)$


이러한 과정을 반복해 정렬을 완료한다.
구현 코드
array = [7, 5, 9, 0, 3, 1, 6, 2, 4, 8]
for i in range(len(array)):
min_index = i # 가장 작은 원소의 인덱스
for j in range(i + 1, len(array)):
if array[min_index] > array[j]:
min_index = j
# swap
array[i], array[min_index] = array[min_index], array[i]
print(array)2. 삽입 정렬
처리 되지 않은 데이터를 하나씩 골라 적절한 위치에 삽입한다.
선택 정렬에 비해 구현 난이도가 높은 편이지만, 일반적으로 더 효율적으로 동작한다.
현재 리스트의 데이터가 거의 정렬되어 있는 상태에서 매우 빠르게 동작
- 시간 복잡도 : $ O(N^2) $
- 최선의 경우(정렬이 되어 있는 경우) : $O(N)$

구현 코드
array = [7, 5, 9, 0, 3, 1, 6, 2, 4, 8]
# 2번째 원소부터 시작
for i in range(1, len(array)):
for j in range(i, 0, -1): # 인덱스 i부터 1까지 1씩 감소하며 반복(거꾸로)
if array[j] < array[j-1]: # 한 칸씩 왼쪽으로 이동
array[j], array[j-1] = array[j-1], array[j]
else:
# 자기보다 작은 데이터를 만났을 경우, 그 위치에서 멈춤
break
print(array)3. 퀵 정렬
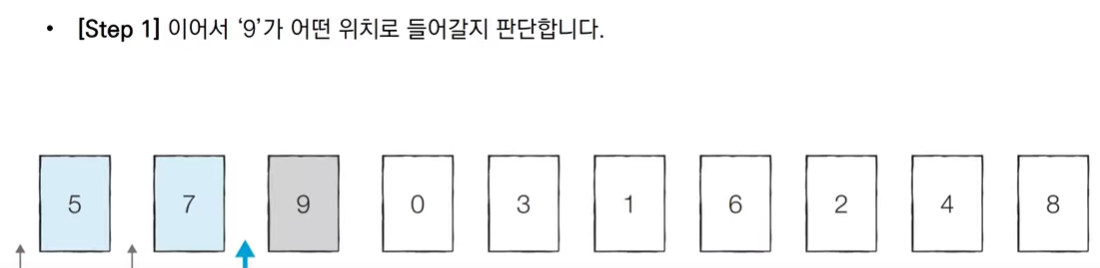
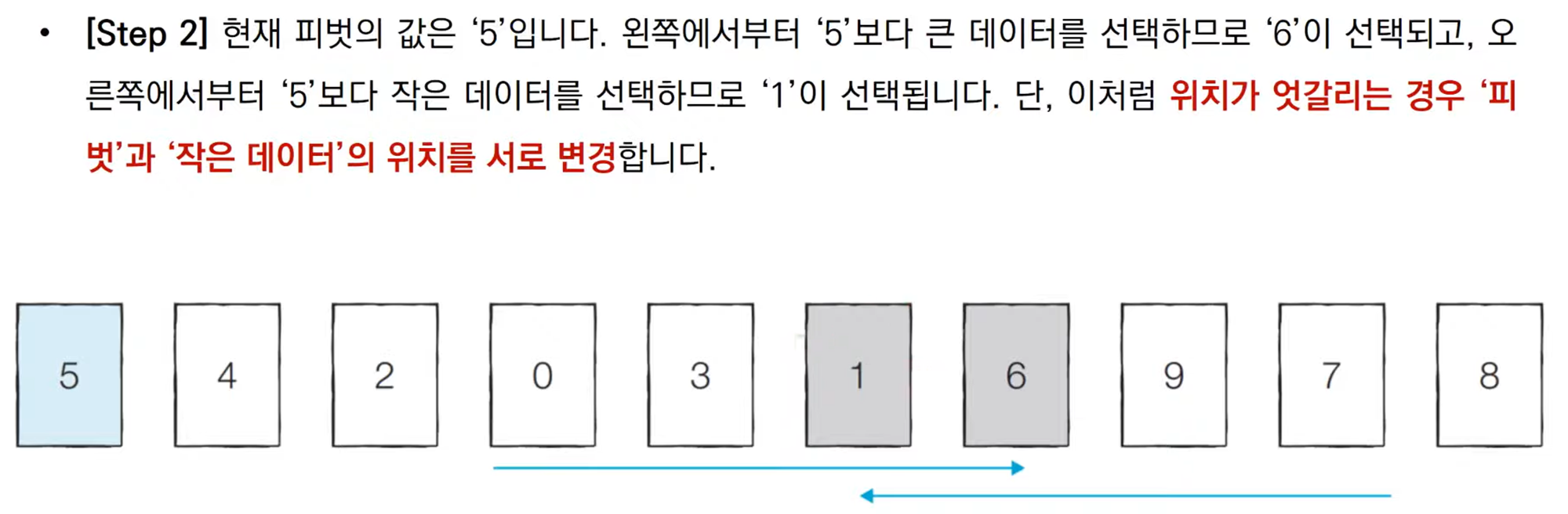
기준 데이터를 설정하고그 기준보다 큰 데이터와 작은 데이터의 위치를 바꾸는 방법
일반적인 상황에서 가장 많이 사용되는 정렬 알고리즘 중 하나
첫 번째 데이터를 기준 데이터(Pivot)로 설정한다.
- 시간 복잡도 : $O(NlogN)$
- 최악의 경우 : $O(N^2)$
**=> 첫 번째 원소가 pivot일 때, 분할이 절반에 가깝게 이뤄지지 않고 한쪽 방향으로 편향된 분할이 발생할 수 있다.**



구현 코드1
array = [7, 5, 9, 0, 3, 1, 6, 2, 4, 8]
def quick_sort(array, start, end):
if start >= end: # 원소가 1개인 경우 종료
return
pivot = start # 피벗은 첫번째 원소
left = start + 1
right = end
while left <= right:
# 피벗보다 큰 데이터를 찾을 때까지 반복
while (left <= end) and (array[left] <= array[pivot]):
left += 1
# 피벗보다 작은 데이터를 찾을 때까지 반복
while (right > start) and (array[right] >= array[pivot]):
right -= 1
if left > right: # 엇갈렸다면 작은 데이터와 피벗을 교체
array[right], array[pivot] = array[pivot], array[right]
else: # 엇갈리지 않았다면 작은 데이터와 큰 데이터를 교체
array[left], array[right] = array[right], array[left]
# 분할 이후 왼쪽 부분과 오른쪽 부분에서 각각 정렬 수행
quick_sort(array, start, right - 1)
quick_sort(array, right + 1, end)
quick_sort(array, 0, len(array) - 1)
print(array)구현 코드2 - 파이썬의 장점을 살린 방식
array = [7, 5, 9, 0, 3, 1, 6, 2, 4, 8]
def quick_sort(array):
# 리스트가 하나 이하의 원소만을 담고 있다면 종료
if len(array) <= 1:
return array
pivot = array[0] # 피벗은 첫번째 원소
tail = array[1:] # 피벗을 제외한 리스트
left_side = [x for x in tail if x <= pivot] # 분할된 왼쪽 부분
right_side = [x for x in tail if x > pivot] # 분할된 오른쪽 부분
# 분할 이후 왼쪽 부분과 오른쪽 부분에서 각각 정렬 수행하고, 전체 리스트 반환
return quick_sort(left_side) + [pivot] + quick_sort(right_side)
print(quick_sort(array))4. 계수 정렬
특정한 조건이 부합할 때만 사용할 수 있지만, 매우 빠르게 동작하는 정렬 알고리즘
- 계수 정렬은 데이터 크기 범위가 제한되어 정수 형태로 표현할 수 있을 때 사용 가능
- 동일한 값을 가지는 데이터가 여러 개 등장할 때 효과적으로 사용 가능 ex) 성적 : 100점 맞은 학생이 여러명일 수 있기 때문
- 그러나 때에 따라서 심각한 비효율성을 초래한다. ex) 데이터가 0과 999,999 단 2개만 존재할 경우
- 시간 복잡도 : 데이터의 개수가 N, 데이터(양수) 중 최댓값이 K일 때 최악의 경우에도 수행 시간 $O(N + K)$를 보장한다.
- 공간 복잡도 : $O(N + K)$

각 숫자가 몇번 등장했는 지 count를 진행한다


구현 코드
# 모든 원소의 값이 0보다 크거나 같다고 가정
array = [7, 5, 9, 0, 3, 1, 6, 2, 9, 1, 4, 8, 0, 5, 2]
# 모든 범위를 포함하는 리스트 선언(모든 값은 0으로 초기화
count = [0] * (max(array) + 1)
for i in range(len(array)):
# 각 데이터에 해당하는 인덱스 값이 증가
count[array[i]] += 1
for i in range(len(count)): # 리스트에 기록된 정렬 정보 확인
for j in range(count[i]):
print(i, end=' ') # 등장한 횟수만큼 인덱스 출력데이터의 개수만큼 하나씩 count 체크 : $O(N)$
각 인덱스를 count의 최대값 k만큼 확인해 출력 : $O(K + N)$

| 정렬 알고리즘 | 평균 시간 복잡도 | 공간 복잡도 | 특징 |
|---|---|---|---|
| 선택 정렬 | O(N^2) | O(N) | 매우 간단한 아이디어 |
| 삽입 정렬 | O(N^2) | O(N) | 데이터가 거의 정렬되어 있을 때 가장 빠름 |
| 퀵 정렬 | O(NlogN) | O(N) | 대부분의 경우에 가장 적합하고, 충분히 빠름 |
| 계수 정렬 | O(N + K) (K는 데이터의 최대값) | O(N + K) (K는 데이터의 최대값) | 데이터의 크기가 한정되어 있는 경우에만 사용 가능 but, 매우 빠르게 동작 |
'알고리즘' 카테고리의 다른 글
| [이코테] 8장 다이나믹 프로그래밍(동적 계획법) (0) | 2023.05.01 |
|---|---|
| [SQL] 그룹별 조건에 맞는 식당 목록 출력하기★ (0) | 2023.04.07 |
| [이코테] 5장 DFS/BFS (0) | 2023.01.16 |
| [Python] 백준 11047번 동전 0 (0) | 2022.12.02 |
| [이코테] 3장 그리디 (0) | 2022.12.02 |
![[이코테] 5장 DFS/BFS](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FMizH2%2FbtrWq30MdIQ%2FAAAAAAAAAAAAAAAAAAAAACiK3SCX0OOTiiAdbytTPxBAnJsDhzd3RUcqPR_-p7xS%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3DrbLT1SSIHxLlWiFnxVgLd7ywxE8%253D)